In Java we have the option to add or change the code we are compiling during compilation. It allows us to add new code based upon annotations in the code. This could for example be used to generate some proxy classes, or setting up some service loader files.
In this post we will be looking at annotation processing to create a light-weight and very simplistic bean context.
Note: if you are looking for a CDI framework please don’t use the example in this post but look at Guice or Spring instead.
See the full code on GitHub: gjong/demo-compile-time-annotation-processor.
Preparing for annotation processing
Before you can actually perform any type of annotation scanning you first have to setup the annotation that you want to scan. In this example the annotation below will be used, the @Target indicates it can only be set at the class level.
1@Target(ElementType.TYPE)
2@Retention(RetentionPolicy.SOURCE)
3public @interface Bean {
4 String name();
5 boolean shared() default true;
6}
Aside from the Bean annotation for this example we need an interface CdiBean that we can use to implement for all found classes annotated.
This CdiBean will contain the needed information to create an instance of the actual class annotated, as well as some type and qualifier information that allows us to identify it properly.
1public interface CdiBean<T> {
2 T create(BeanProvider provider);
3 Class<T> type();
4 String qualifier();
5}
We also need a class that is used to locate classes that were annotated with the Bean. To do this the following BeanProvider interface is created.
1public interface BeanProvider {
2 <T> T provide(String qualifier);
3 <T> T provide(Class<T> clazz);
4}
Setting up the annotation scanner
To add annotation scanning during compilation of code you need to implement a AbstractProcessor. The basic setup should look something similar to the code snippet below.
1@SupportedAnnotationTypes("com.github.gjong.cdi.Bean")
2@SupportedSourceVersion(SourceVersion.RELEASE_21)
3public class BeanProcessor extends AbstractProcessor {
4
5 private boolean processCompleted;
6
7 @Override
8 public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
9 if (processCompleted) {
10 return false;
11 }
12
13 try {
14 // the actual scanning logic will be implemented here
15 processCompleted = true;
16 } catch (Exception e) {
17 processingEnv.getMessager()
18 .printMessage(Diagnostic.Kind.ERROR, "Exception occurred %s".formatted(e));
19 }
20
21 return false;
22 }
The SupportedAnnotationTypes allows you to indicate in what annotation you are interested. In our example this is the Bean annotation, we want to consume any class file that contains that annotation.
The process() method will get called for each compilation round when the compiler detects the wanted Bean annotation. Do note that the compiler may be triggering this method multiple times as it may go through several compilation rounds. Keep in mind that the fact that we are annotation processing and generating new source code will trigger another compiler round. See the diagram below for a graphical explanation of the cycles.
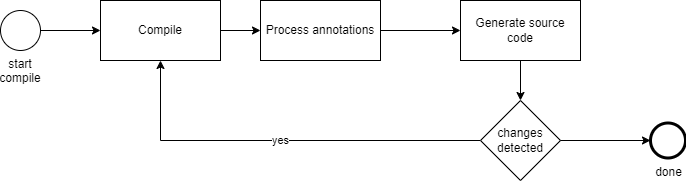
So lets add some code to actually fetch all the classes that have our Bean annotation on it. The snippet below is part of the process() method.
1var resolver = new TypeDependencyResolver();
2var beanDefinitions = annotations.parallelStream()
3 .map(roundEnv::getElementsAnnotatedWith)
4 .flatMap(element -> ElementFilter.typesIn(element).stream())
5 .map(typeElement -> resolver.resolve(typeElement, processingEnv.getMessager()))
6 .toList();
In this part of the code we fetch all annotations we want, which should only yield the Bean annotation. For each one of these annotations we request all Element that use the annotation. We then convert these elements to TypeElement instances, that allow access to the structure of the class.
Processing the annotated classes
For the translating of the TypeElement to something that is more suitable for generating code later on the TypeDependencyResolver class is introduced.
We will store the needed information of the class described by the TypeElement in a BeanDefinition. This will have the required arguments to construct an instance of the class.
1public record BeanDefinition(TypeElement type, List<ArgumentDefinition> dependencies) {
2
3 public record ArgumentDefinition(TypeMirror type, Qualifier qualifier) {
4 }
5
6 public Bean getBean() {
7 return type.getAnnotation(Bean.class);
8 }
9}
In this class a method resolveConstructor is added to figure out what constructors exist on the class represented by the TypeElement. This code looks for all constructors that are not private, if multiple constructors exist it will favour the one marked with a Inject annotation.
1private Optional<ExecutableElement> resolveConstructor(TypeElement typeElement) {
2 var constructors = ElementFilter.constructorsIn(typeElement.getEnclosedElements());
3 constructors.removeIf(constructor -> constructor.getModifiers().contains(Modifier.PRIVATE));
4
5 var noArgsConstructor = constructors.stream()
6 .filter(constructor -> constructor.getParameters().isEmpty())
7 .findFirst();
8 var injectConstructor = constructors.stream()
9 .filter(constructor -> constructor.getAnnotation(Inject.class) != null)
10 .findFirst();
11
12 return injectConstructor.or(() -> noArgsConstructor);
13}
The next step in this translation process is to add a method resolveClass to create a BeanDefinition of the class we are investigating.
1private BeanDefinition resolveClass(TypeElement typeElement, Messager messager) {
2 var constructor = resolveConstructor(typeElement)
3 .orElseThrow(() -> {
4 messager.printMessage(ERROR, "Class %s must have a public constructor".formatted(typeElement));
5 return RESOLVE_FAILED;
6 });
7
8 var dependencies = constructor.getParameters()
9 .stream()
10 .map(arg -> new BeanDefinition.ArgumentDefinition(arg.asType(), arg.getAnnotation(Qualifier.class)))
11 .toList();
12
13 return new BeanDefinition(typeElement, dependencies);
14}
Using this resolveClass we can finalize the TypeDependencyResolver by adding the resolve method that translates the TypeElement into a BeanDefinition.
1class TypeDependencyResolver {
2 private static final IllegalStateException RESOLVE_FAILED = new IllegalStateException("Failed to resolve dependency.");
3
4 public BeanDefinition resolve(TypeElement typeElement, Messager messager) {
5 if (typeElement.getKind().isClass() && !typeElement.getModifiers().contains(Modifier.ABSTRACT)) {
6 return resolveClass(typeElement, messager);
7 }
8
9 messager.printMessage(ERROR, "Class %s must not be abstract".formatted(typeElement));
10 throw RESOLVE_FAILED;
11 }
12 // the other methods described above
13}
Writing the bean proxy
Since the writing of source code is a bit convoluted and noisy with all the print instructions it is separated in the BeanProxyWriter class. The basic structure of the class is as follows:
1 class BeanProxyWriter {
2 private final BeanDefinition definition;
3 private final String definedClassName;
4 private final Function<BeanDefinition.ArgumentDefinition, String> parameterResolver;
5
6 public BeanProxyWriter(BeanDefinition definition) {
7 this.definition = definition;
8 this.definedClassName = "%s$Proxy".formatted(definition.type().getSimpleName());
9 this.parameterResolver = typeMirror -> Optional.ofNullable(typeMirror.qualifier())
10 .map(qualifier -> "provider.provide(\"%s\")".formatted(qualifier.value()))
11 .orElseGet(() -> "provider.provide(%s.class)".formatted(typeMirror.type()));
12 }
13
14 void writeSourceFile(ProcessingEnvironment environment) {
15 // added later on
16 }
17
18 private void createConstructor(PrintWriter writer, TypeElement solutionClass) {
19 // added later on
20 }
21}
Lets add the piece of code that generates the constructor call for the class. In this createConstructor method we consume the TypeElement and add the constructor call to it, using the arguments that we stored previously in the BeanDefinition.
1private void createConstructor(PrintWriter writer, TypeElement solutionClass) {
2 writer.print("new %s(".formatted(solutionClass.getSimpleName()));
3 for (var it = definition.dependencies().iterator(); it.hasNext(); ) {
4 writer.print(parameterResolver.apply(it.next()));
5 if (it.hasNext()) {
6 writer.print(",");
7 }
8 }
9 writer.print(")");
10}
Now that we can write the constructor it is time to add the code to add the actual proxy source file. The writeSourceFile opens a file using the ProcessingEnvironment (line 7) and wraps it in a PrintWriter.
1void writeSourceFile(ProcessingEnvironment environment) {
2 var packageName = environment.getElementUtils().getPackageOf(definition.type()).getQualifiedName();
3 var fileName = packageName + "." + definedClassName;
4 var beanClass = definition.type();
5 var bean = definition.getBean();
6
7 try (var writer = new PrintWriter(environment.getFiler().createSourceFile(fileName).openWriter())) {
8 writer.println("package %s;".formatted(packageName));
9 writer.println();
10 writer.println("import com.github.gjong.cdi.BeanProvider;");
11 writer.println("import com.github.gjong.cdi.context.CdiBean;");
12 writer.println("import com.github.gjong.cdi.context.SingletonProvider;");
13 writer.println();
14 writer.println("import %s;".formatted(beanClass));
15 writer.println();
16 writer.println("public class %s implements CdiBean<%s> {".formatted(definedClassName, beanClass.getSimpleName()));
17 writer.println();
18
19 writer.println(" private final SingletonProvider<%s> singletonProvider;".formatted(beanClass.getSimpleName()));
20
21 writer.println();
22 writer.println(" public %s() {".formatted(definedClassName));
23 if (bean.shared()) {
24 writer.println(" singletonProvider = new SingletonProvider() {");
25 writer.println(" private %s instance;".formatted(beanClass.getSimpleName()));
26 writer.println(" public %s provide(BeanProvider provider) {".formatted(beanClass.getSimpleName()));
27 writer.println(" if (instance == null) {");
28 writer.print(" instance = ");
29 createConstructor(writer, beanClass);
30 writer.println(";");
31 writer.println(" }");
32 writer.println(" return instance;");
33 writer.println(" }");
34 writer.println(" };");
35 } else {
36 writer.println(" singletonProvider = new SingletonProvider() {");
37 writer.println(" public %s provide(BeanProvider provider) {".formatted(beanClass.getSimpleName()));
38 writer.print(" return ");
39 createConstructor(writer, beanClass);
40 writer.println(";");
41 writer.println(" }");
42 writer.println(" };");
43 }
44 writer.println(" }");
45
46 writer.println(" public %s create(BeanProvider provider) {".formatted(beanClass.getSimpleName()));
47 writer.println(" return singletonProvider.provide(provider);");
48 writer.println(" }");
49 writer.println();
50 writer.println(" public Class<%s> type() {".formatted(beanClass.getSimpleName()));
51 writer.println(" return %s.class;".formatted(beanClass.getSimpleName()));
52 writer.println(" }");
53 writer.println();
54 writer.println(" public String qualifier() {");
55 writer.println(" return \"%s\";".formatted(bean.name()));
56 writer.println(" }");
57 writer.println("}");
58 } catch (IOException e) {
59 throw new RuntimeException(e);
60 }
61}
Essentially this method creates a source file for each class annotated with Bean, where the added file uses the same package and name as the original class. But it adds the $Proxy to make it unique. The created proxy class implements the CdiBean interface.
Finalizing the annotation processor
Since all the pieces are in play right now it is time to update the BeanProcessor class. First we will be implementing a piece of code that will actually trigger the writing of all the new source proxy files.
1private void writeProxyClasses(List<BeanDefinition> beanDefinitions) {
2 for (var beanDefinition : beanDefinitions) {
3 new BeanProxyWriter(beanDefinition).writeSourceFile(processingEnv);
4 }
5}
Also add the writeProxyClasses(beanDefinitions); call to the process method. This will generate the proxy source files for all classes annotated with Bean.
To make using of the newly created proxy classes we also want to write a service loader file. This can be done by adding the following method in the BeanProcessor:
1private void writeServiceLoader(List<BeanDefinition> beanDefinitions) {
2 try (var serviceWriter = new PrintWriter(processingEnv.getFiler()
3 .createResource(StandardLocation.CLASS_OUTPUT,
4 "",
5 "META-INF/services/com.github.gjong.cdi.context.CdiBean")
6 .openWriter())) {
7 beanDefinitions.forEach(type -> serviceWriter.println(
8 "%s.%s$Proxy".formatted(
9 processingEnv.getElementUtils().getPackageOf(type.type()).getQualifiedName(),
10 type.type().getSimpleName())));
11 } catch (Exception e) {
12 processingEnv.getMessager()
13 .printMessage(Diagnostic.Kind.ERROR, "Exception occurred %s".formatted(e));
14 }
15}
The last step is to create an implementation of the BeanProvider to allow us to actually access the proxy classes. The BeanContext will get a method initialize that uses the service loader mechanism to detect all proxy beans and store them in an internal list.
1public class BeanContext implements BeanProvider {
2 private final List<CdiBean<?>> knownBeans = new ArrayList<>();
3
4 public void initialize() {
5 ServiceLoader.load(CdiBean.class)
6 .forEach(knownBeans::add);
7 }
8
9 @Override
10 @SuppressWarnings("unchecked")
11 public <T> T provide(String qualifier) {
12 return (T) knownBeans.stream()
13 .filter(b -> Objects.equals(qualifier, b.qualifier()))
14 .findFirst()
15 .map(b -> b.create(this))
16 .orElseThrow(() -> new IllegalArgumentException("No bean found for " + qualifier));
17 }
18
19 @Override
20 @SuppressWarnings("unchecked")
21 public <T> T provide(Class<T> clazz) {
22 var matchingBeans = knownBeans.stream()
23 .filter(b -> clazz.isAssignableFrom(b.type()))
24 .toList();
25 if (matchingBeans.size() > 1) {
26 throw new IllegalArgumentException("Multiple beans found for " + clazz);
27 } else if (matchingBeans.isEmpty()) {
28 throw new IllegalArgumentException("No bean found for " + clazz);
29 }
30
31 return (T) matchingBeans.getFirst()
32 .create(this);
33 }
34}
Both the provide() methods will use the internal list to locate a bean that matches either the qualifier name or the bean Class type.